OverView
이번시간에는 데이터베이스의 Index에 대해서 알아보도록 하겠다.
Index
인덱스는 한자어로 색인이라는 뜻을 갖고 있다.
색인(索引)은 책 속의 낱말이나 구절, 또 이에 관련한 지시자를 찾아보기 쉽도록 일정한 순서로 나열한 목록을 가리킨다. 인덱스(index)라고도 한다.
https://ko.wikipedia.org/wiki/%EC%83%89%EC%9D%B8
색인 또는 목록이라는 의미이며, 데이터를 기록할 경우 그 데이터의 이름, 데이터 크기 등의 속성과 그 기록 장소 등을 표로 표시하는 것. 즉 참조용의 데이터를 색인표 또는 인덱스라 한다.
https://terms.naver.com/entry.nhn?docId=825626&cid=42344&categoryId=42344
책에서 특정 부분을 빠르게 찾기 위해서 책의 목차를 먼저 살펴보고 목차에 표기된 책 페이지번호로 넘어가는 과정이 데이터베이스에도 똑같이 있다. 이걸 Index라고한다.
인덱스는 B-Tree(Balanced-Tree)형이라는 자료구조를 사용하는데 기본적으로 이진탐색트리라는 자료구조에 대한 지식이 있어야 한다. 이진탐색트리는 검색시 효율이 최적의 상태일때 O(log n)이 나오는 자료구조이다. 이진탐색트리에 대한 이해가 있다면 B-tree를 이해하는 것은 크게 어렵지 않을 것 같다. B-Tree 관련해서 매우 좋은글이 있으니 https://hyungjoon6876.github.io/jlog/2018/07/20/btree.html 이곳을 참고하면 좋을듯 하다.
B-Tree
B-Tree를 요약하면 다음과 같다.
- 노드 내 데이터가 1개 이상일 수 있다.
- 노드 내 최대 데이터 수가 2개라면 2차 B-Tree, 3개라면 3차 B-Tree라고 한다.
- 노드의 데이터수가 n개라면 자식 노드의 개수는 n + 1개다.
- 노드 내 데이터는 반드시 정렬된 상태이다.
- 노드 내 데이터들보다 작은 데이터들은 노드의 왼쪽에 위치하고 노드 내 데이터들보다 큰 데이터들은 노드의 오른쪽에 위치한다. (이진탐색트리와 비슷함)
- 단말 노드들은 전부 같은 레벨이어야 한다.
- 루트 노드가 자식이 있다면 적어도 2개 이상의 자식을 가져야 한다.
- 입력 자료는 중복이 될 수 없다.
- 루트를 제외한 모든 노드들은 M/2개의 데이터를 갖고 있어야한다. (M은 처음에 지정한 최대 데이터의 수)
이진탐색트리는 최악의 경우 O(n)이지만 B-Tree는 항상 log n을 반환하도록 되어 있다. 따라서 검색에 최적화된 자료구조라고 할 수 있다. 아래 표를 확인해보자.
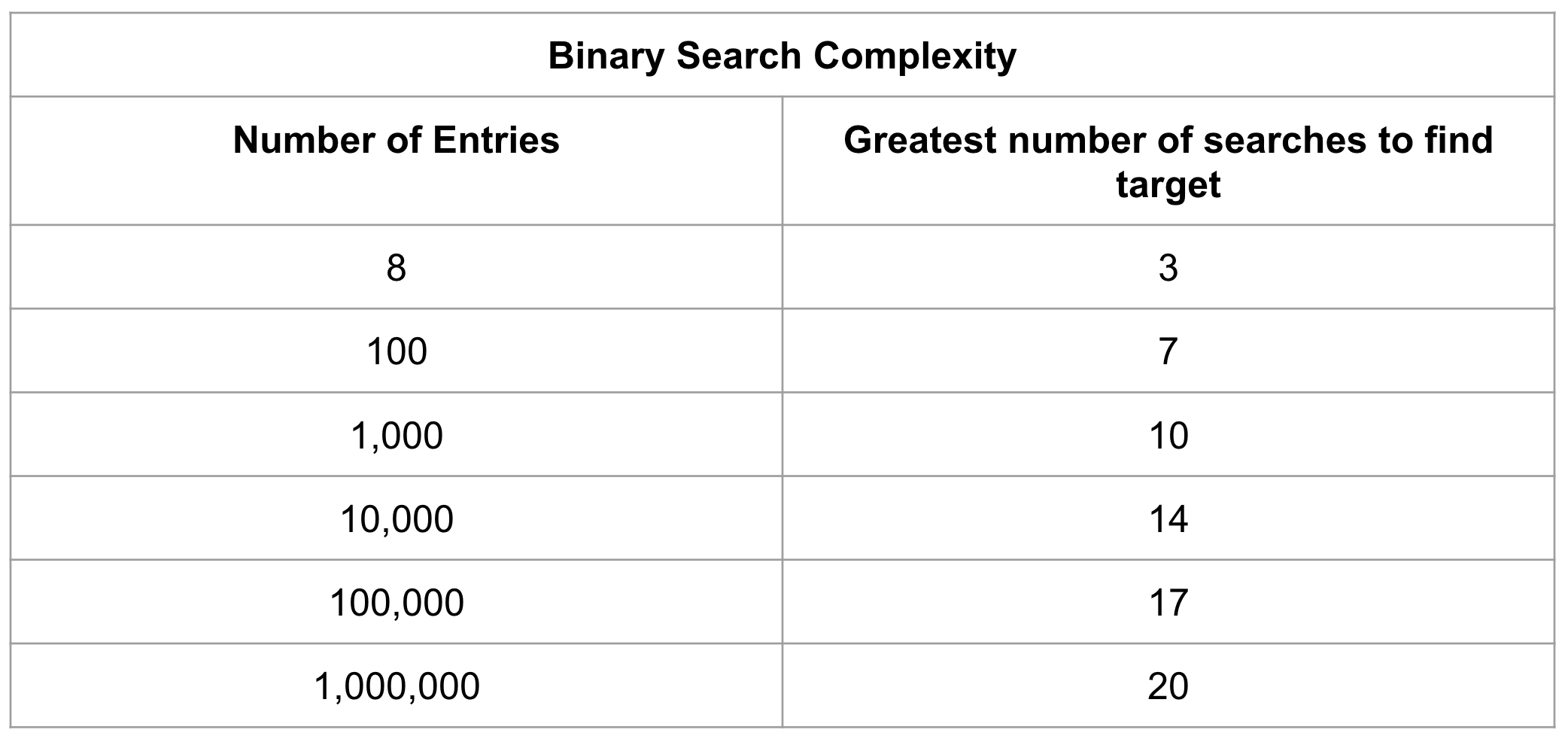
B-Tree에서 삽입 삭제가 어떻게 이루어지는지 눈으로 확인하고 싶다면 https://www.cs.usfca.edu/~galles/visualization/BTree.html에서 아주 간편하게 확인할 수 있다.
Index 생성하기
※테스트는 MySQL로 진행했다.
먼저 다음과 같은 테이블이 있다고 가정하고 진행한다.
CREATE TABLE EMP
(EMPNO INT(50) NOT NULL primary key auto_increment,
ENAME VARCHAR(100),
JOB VARCHAR(100));
이 EMP 테이블에는 총 약 300만건의 데이터가 있다.
먼저 아무런 index를 부여하지 않았을때 단순히 테이블 로우 수 / 2 있는 회원정보를 ENAME 컬럼을 통해서 가져오는데 걸리는시간은 아래와 같다.
-- 1,400,000번째 회원
select * from emp where ename = 'QHJX304482';
| 수행시간 |
|---|
| 1.172 sec / 0.000 sec |
| 1.157 sec / 0.000 sec |
| 1.172 sec / 0.000 sec |
| 1.141 sec / 0.000 sec |
| 1.140 sec / 0.000 sec |
평균적으로 약 1.5초의 시간이 걸린다.
이제 다음과같이 인덱스를 설정하고 다시한번 조회해보자.
alter table emp add index idx_emp_ENAME (ename);
수행시간이 매우 빠르게 단축된것을 확인할 수 있다.
| 수행시간 |
|---|
| 0.000 sec / 0.000 sec |
| 0.000 sec / 0.000 sec |
| 0.000 sec / 0.000 sec |
| 0.000 sec / 0.000 sec |
| 0.000 sec / 0.000 sec |
Index 확인하기
Index를 확인하는 방법은 다음 sql을 통해서 확인할 수 있다.
show index from <테이블명>

결과는 다음과 같은데 우리가 이전에 생성한 idx_emp_ENAME 외에도 PRIMARY라는 인덱스가 자동으로 들어가 있다.
Clustered Index
위에서 확인할 수 있는 것처럼 PRIMARY라는 이름을 가진 인덱스가 자동으로 잡히는데 테이블 DDL을 다시 확인해보면 EMPNO가 pk로 잡힌것을 확인할 수 있다.
CREATE TABLE EMP
(EMPNO INT(50) NOT NULL primary key auto_increment,
ENAME VARCHAR(100),
JOB VARCHAR(100));
Clustered Index의 정의는 다음과 같다.
- 테이블의 데이터를 지정된 컬럼에 대해 물리적으로 재배열시킨다. 삽입, 수정, 삭제시 실제 테이블의 데이터를 정렬한다.
- 테이블 당 한개만 존재한다.
- 기본적으로 PK값이 Clustered Index로 잡힌다.
Non-Clustered Index
우리가 직접 추가한 idx_emp_ENAME는 Non-Clustered Index에 해당한다.
Non-Clustered Index의 정의는 다음과 같다.
- 테이블의 데이터를 지정된 컬럼에 대해 물리적으로 재배열하지 않고 별도로 정렬된 인덱스를 생성한다. 삽입, 수정, 삭제시 실제 테이블의 정렬이 없다
- 테이블 당 여러개가 있을 수 있다.
Index Cardinality
다시 index를 확인해보면 중간쯤에 Cardinality라는 값이 있다.
이 Cardinality라는 값은 Index 설정에서 꽤 중요한 부분인데 다음과 같은 개념이다
- 중복도가 ‘낮으면’ 카디널리티가 ‘높다’고 표현한다.
- 중복도가 ‘높으면’ 카디널리티가 ‘낮다’고 표현한다.
EMPNO 은 pk이기 때문에 데이터의 중복도가 0에 가깝다 따라서 높은 카디널리티 값을 갖고 ENAME은 중복도가 어느정도 있기때문에 낮은 카디널리티를 갖는다.
인덱스를 설정할 컬럼을 N개 지정할 수 있는데 어떤 컬럼에 먼저 설정할지에 따라 SELECT 성능을 좌우할 수 있다. https://itholic.github.io/database-cardinality/ 여기에서는 왜 카디널리티가 높은 인덱스를 순차적으로 잡아줘야하는지 잘 설명되어 있다.
결론적으로 중복도가 낮은 컬럼에 인덱스를 설정하는 것이 좋은 성능을 가져올 수 있다.
마무리
너무 잘 설명되어있는 글들이 많아서 참조를 많이 했다.
포스팅은 여기까지 하겠습니다. 퍼가실때는 출처를 반드시 남겨주세요!
References